又是鸽了将近一个月了,今天来写点不一样的,CSDN爬虫。这大概是我这个博客网站上第一次出现Python项目吧,之后我会再更新一个长一点的,Python蒲丰投针,这是我已经完成的一个学校项目。
本人不经常上CSDN,但偶尔需要搜一些资料不可避免的就会搜到相关的链接。但不幸的是,本人没有CSDN的号,无法直接复制代码块的内容,这就非常的麻烦。当然不用爬虫肯定也是有办法的,但极其的麻烦也很浪费时间,我个人觉得这是比较烦的。所以我就上网搜到了一个爬虫,可以直接下载CSDN文章的全文。
注:爬虫这个技术还是比较敏感的——下载到的文章请不要用于商业用途,我个人也建议转载时放一下原链接,这样也避免日后的一些问题。
1. 原先我是怎么做的
正常的文章内容是可以复制的,然而,一般人谁会去要那些呢,可不是去白嫖学习代码?(我没有指名道姓是谁)
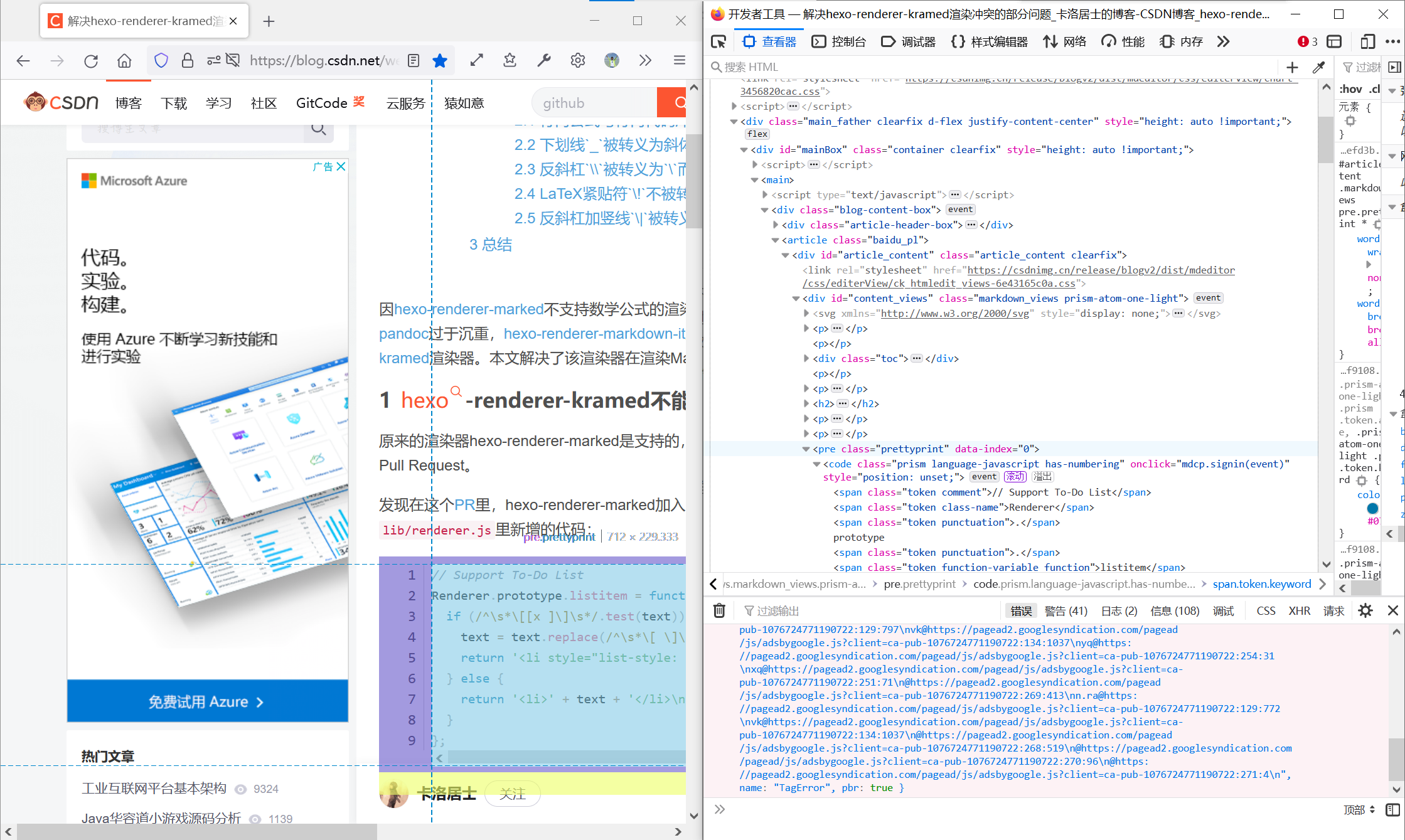
那我真的想要代码怎么办?来看一下一种很麻烦的办法:
![]()
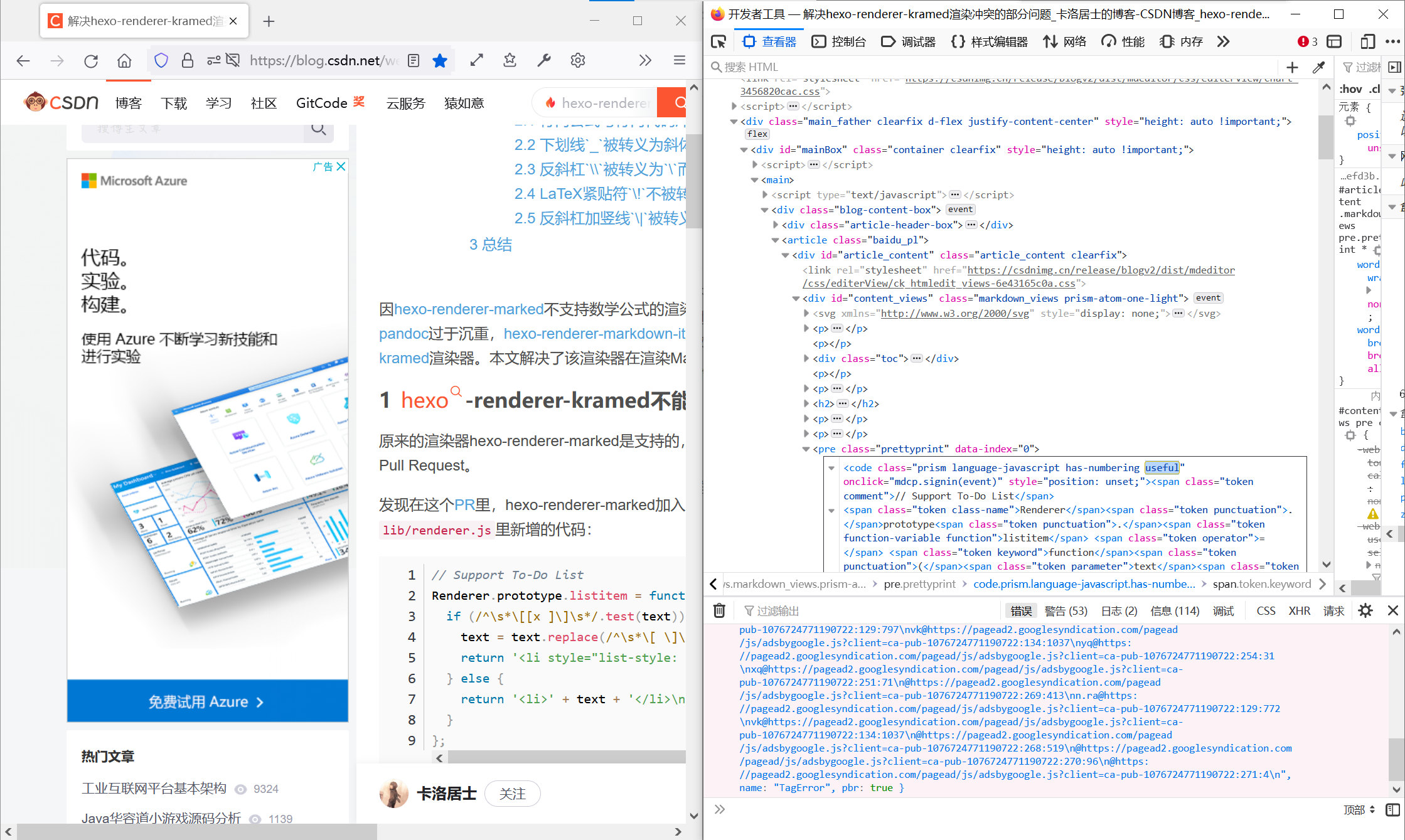
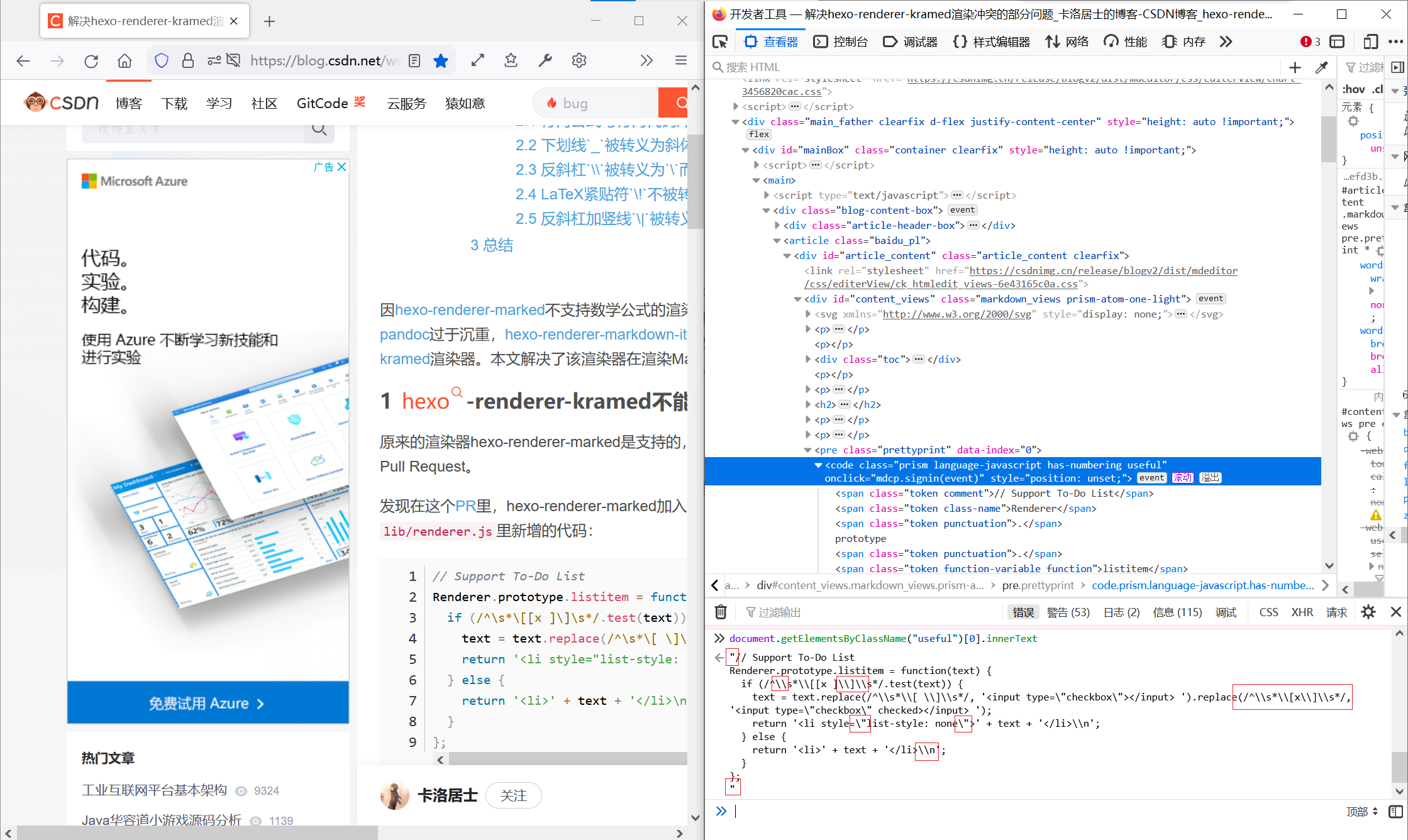
首先不管怎么样我们需要先定位到这个代码块的<pre>元素。但和它同名、同class的元素实在是太多了,怎么办呢?我就加一个useful这个类,区别开来(叫什么其实无所谓)
![]()
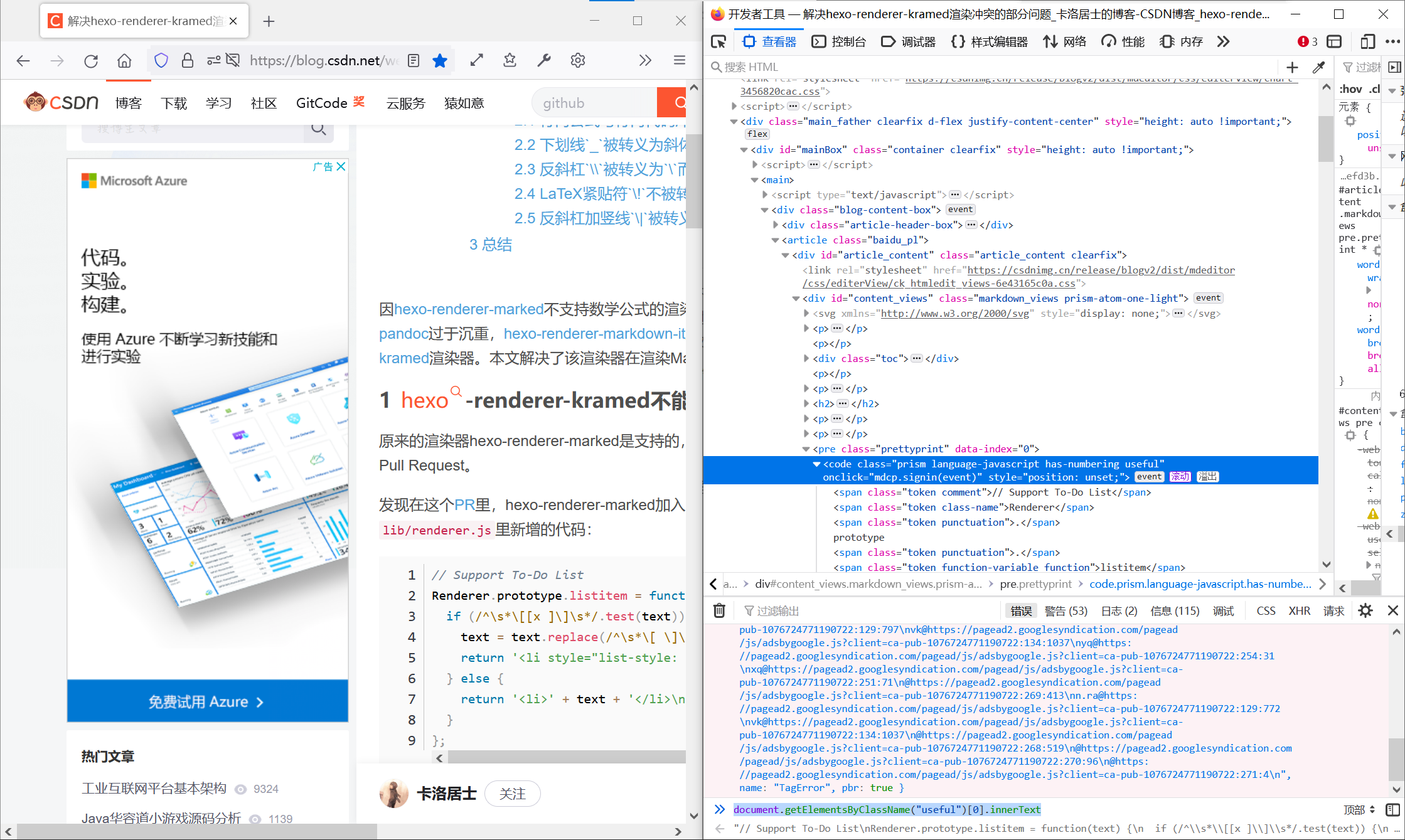
之后的话,我们直接用调试的命令行来找到这个代码块的innerText:
1
| document.getElementsByClassName("useful")[0].innerText
|
![]()
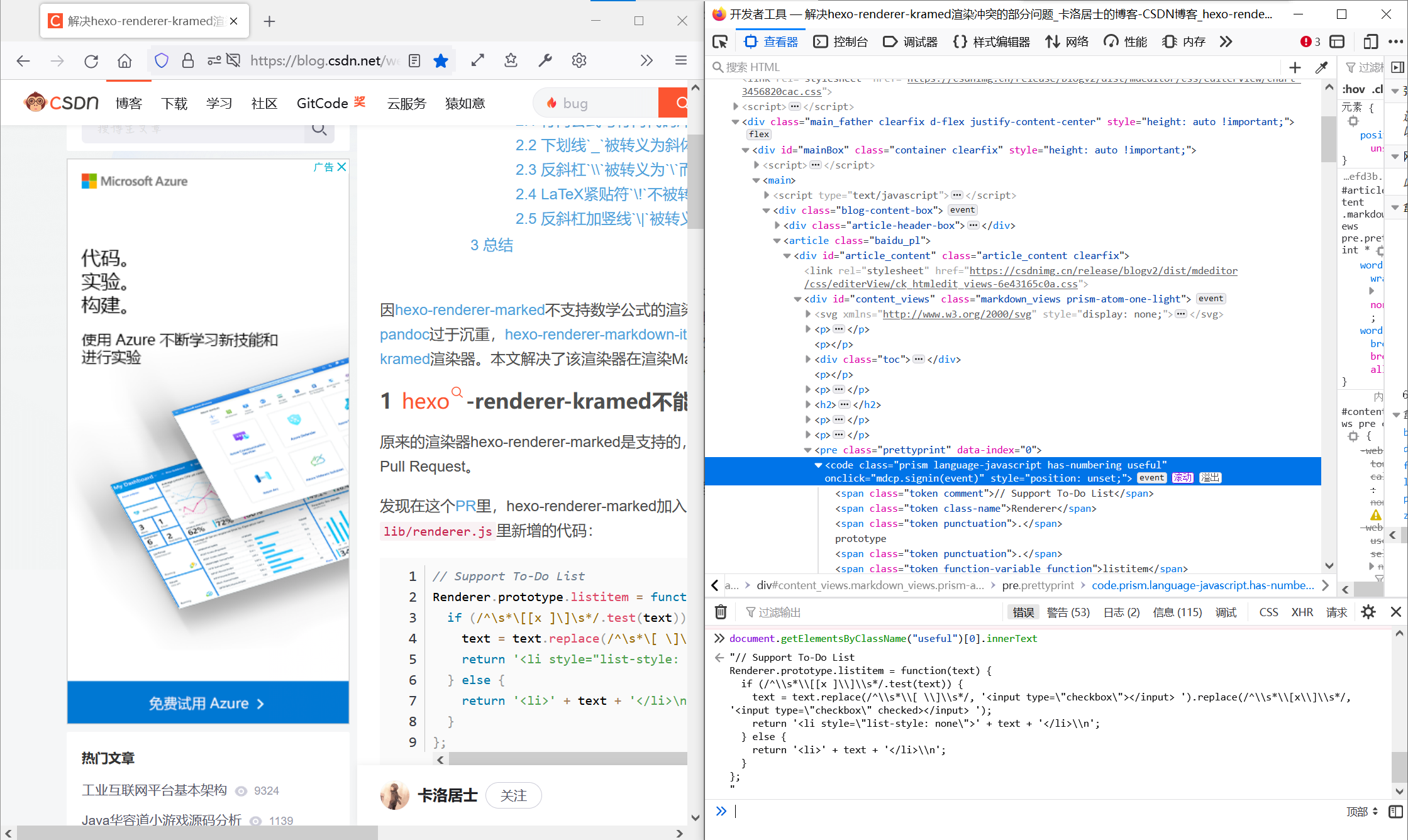
然后我们就获得了这一段代码的内容了。
![]()
但可惜的是——不知道细心的你有没发现——这一整段代码都需要转义(escaping)。红框里的就是用innerText获取到的代码中被自动转义过的地方(未框全):
![]()
当然我肯定有办法反转义,但这实在是太无聊了。然后如果一整篇文章里有太多想要的代码块的话,这个方法也不实用,for in循环也得反转义啊。
所以……出于我的懒惰对爬虫的激情——我就上网搜到了一个(甚至都不是自己写的)。
2. CSDN上的解决方案
对没错,这个爬取CSDN的程序很巧就是从CSDN上来的。原作的话:【python】爬取CSDN博客文章(保存为html,txt,md)_cloudmapleleaf的博客-CSDN博客。我比较喜欢的在于这个HTML转MD的功能,然后它自己是可以自动转义的。我就不让大家去自己折腾了,我这里完全可以一键复制()我自己是进行过一点点小修改的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| import requests
from html2text import HTML2Text
from lxml import etree
from html import unescape
import os
import time
"""
requirements
打了箭头的才需要手动安装,其余是自动安装的依赖库
certifi==2021.10.8
charset-normalizer==2.0.7
cssselect==1.1.0
html2text==2020.1.16 -- <--
idna==3.3
lxml==4.6.3 ----------- <--
requests==2.26.0 ------- <--
urllib3==1.26.7
"""
def crawl(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36",
}
print("crawl...")
response = requests.get(url, headers=headers)
if response.status_code == 200:
html = response.content.decode("utf8")
tree = etree.HTML(html)
print("look for text...")
title = tree.xpath('//*[@id="articleContentId"]/text()')[0]
block = tree.xpath('//*[@id="content_views"]')
ohtml = unescape(etree.tostring(block[0]).decode("utf8"))
text = block[0].xpath('string(.)').strip()
print("title:", title)
save(ohtml, text)
print("finish!")
else:
print("failed!")
def save(html, text):
filename = int(time.time())
if "output" not in os.listdir():
os.mkdir("output")
os.mkdir("output/html")
os.mkdir("output/text")
os.mkdir("output/markdown")
with open(f"output/html/{filename}.html", 'w', encoding='utf8') as html_file:
print("write html...")
html_file.write(html)
with open(f"output/text/{filename}.txt", 'w', encoding='utf8') as txt_file:
print("write text...")
txt_file.write(text)
with open(f"output/markdown/{filename}.md", 'w', encoding='utf8') as md_file:
print("write markdown...")
text_maker = HTML2Text()
md_text = text_maker.handle(html)
md_file.write(md_text)
if __name__ == '__main__':
url = str(input("Url: "))
crawl(url)
|
用之前的话是需要安装3个package的:
1
| pip install lxml html2text requests
|
然后我们就可以方便的复制到我们急需的代码或命令了。不过,如需转载你下载下来的文章,我个人觉得还请放一下原文链接的哦。
3. 图片去水印(不是P图
这是我在爬取文章之后不经意间发现的一个功能。比如我们有下面这样一张图片:
![]()
1
| https://img-blog.csdnimg.cn/b1858e0e5a2a4221bd24f93f89a951c9.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pif6L6w5rWp5a6H,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center
|
有没有觉得后面那个x-oss-process很可疑?话说这个图片的水印竟然是请求时服务器再加上去的,甚至不是上传时水印。我们直接把那些配置都删掉,就可以得到没有水印的图片了。
![]()
THE END感谢您的阅读~